设计Pipeline时需要考虑什么?
当我们设计我们的beam pipeline时,需要考虑的一些基础问题:
- 你的输入数据存储在哪里?这将决定Read在pipeline开始时需要使用哪些类型的转换
- 你的数据是怎么样的?
- 你想用数据做什么?
- 你的输出数据是什么样的,应该存储到哪里?这个决定write在pipeline末端使用哪些类型的transforms
一条基本的Pipeline
最简单的Pipeline体现为一个线性的操作流程。如下图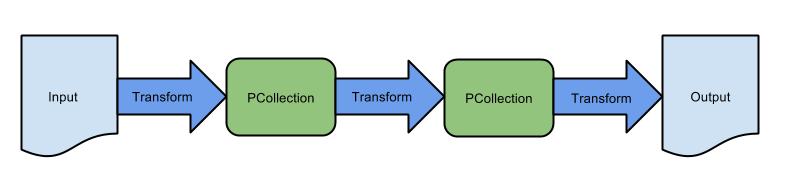
但是,在实际场景中,Pipeline比基本的Pipeline要复杂的多。Pipeline代表一个有步骤的有向无环图。它可能有多个输入源,多个输出接收器,并且其操作PTransforms可以读取和输出多个PCollections。
分支PCollections
重要的是要了解Transforms不消耗PCollections,相反,他们认为每一个独立的元素都是一个PCollection,且创建一个新的PCollection用于输出。这样,我们就可以对同一个PCollection中的不同元素做不同的操作。
多个PTransforms处理相同的PCollections
可以使用相同的PCollection输入用于多个转换,而不消耗输入或更改它。
图中所示的流水线从单个数据库源读取输入数据,并创建一个PCollection表行。然后,Pipeline将多个transforms应用到同一个PCollection。转换a读取所有以A字母开头的PCollection,转换b读取所有以B开头的PCollection。转换a与转换b的输入是同一个PCollection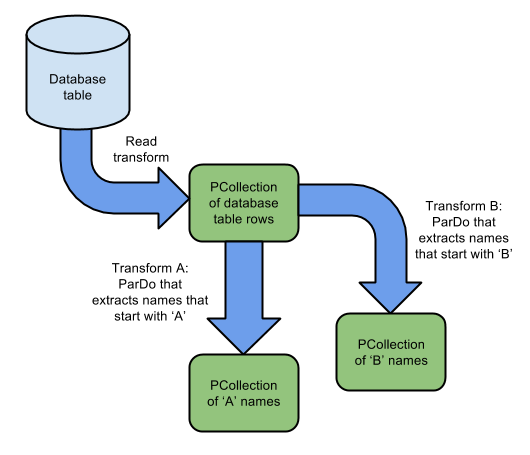
单个PTransforms产生多个输出
分支管道的另一种方法是通过使用带标签的输出将单个变换输出转换为多个。转换产生超过一个的输出处理输入中的每一个元素,以及输出0到多个PCollections
下面的图3示出了上述相同的示例,但是是一个转换产生多个输出。以“A”开头的名称将添加到主输出中PCollection,以“B”开头的名称将添加到其他输出PCollection。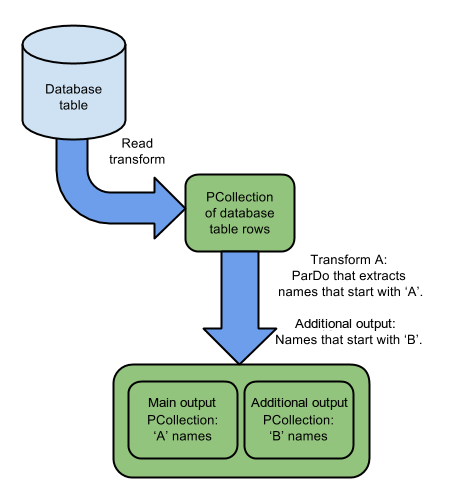
图2中的Pipeline包含两个处理相同PCollection元素的转换,一个转换使用以下逻辑:
而另一个转换则是:
因为每个转换都读取整个PCollection,所以PCollection中的每个元素都被处理两次。
图3中的Pipeline以不同的方式执行相同的操作。下面的逻辑只使用一个转换
其中输入PCollection中的每个元素
您可以使用任一机制来产生多个输出PCollection。然而,如果变换的每个元素的计算是耗时的,则使用额外的输出更有意义
合并PCollections
通常,通过多次转换将PCollection分成多个PCollections后,您将需要将部分或全部PCollections合并在一起。 您可以使用以下方法之一:
- Flatten - 您可以使用Beam SDK中的Flatten变换来合并多个相同类型的PCollections。
- Join - 您可以使用Beam SDK中的CoGroupByKey变换来执行两个PCollections之间的关系连接。 PCollections必须键入(即它们必须是键/值对的集合),并且它们必须使用相同的键类型。
下图中,在分成两个PCollections之后,一个名字以’A’开头,一个名字以’B’开头,管道将两个合并成一个PCollection,现在包含以“A”或“B”。 在这里,使用Flatten是合理的,因为合并的PCollections都包含相同的类型。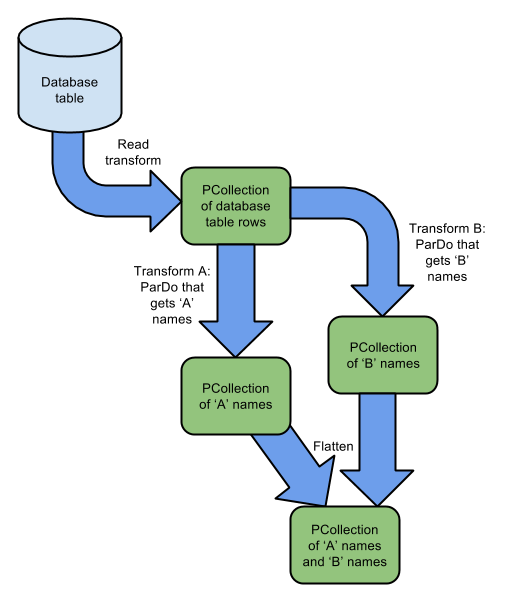
多个来源
管道可以从一个或多个来源读取其输入。 如果管道从多个来源读取,并且来自这些来源的数据是相关的,则可以将输入连接在一起。 在下图所示的示例中,管道从数据库表中读取名称和地址,以及从Kafka主题读取名称和订单号。 然后,管道使用CoGroupByKey来加入这个信息,其中的关键是名称; 结果PCollection包含名称,地址和订单的所有组合。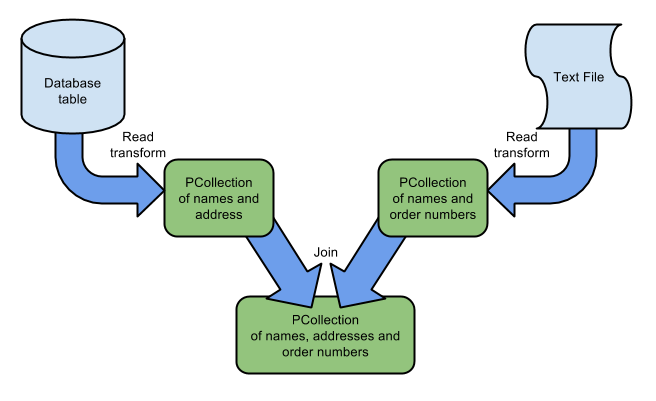
参考链接:
https://beam.apache.org/documentation/pipelines/design-your-pipeline/
