Apache Beam: Portable and Parallel Data Processing
概念说明
在我们做数据流处理的过程中,经常会遇到的一个问题:网络延迟。当然对于无序的数据流来说,网络延迟所带来的数据乱序对结果是不会有太大影响的。但是对于数据顺序有要求的应用,则会导致数据不一致等棘手的问题。
官方给出的一个例子中,包含两个维度:
- 事件事件(Event Time): 事件发生时间
- 处理事件(Processing Time):事件处理时间
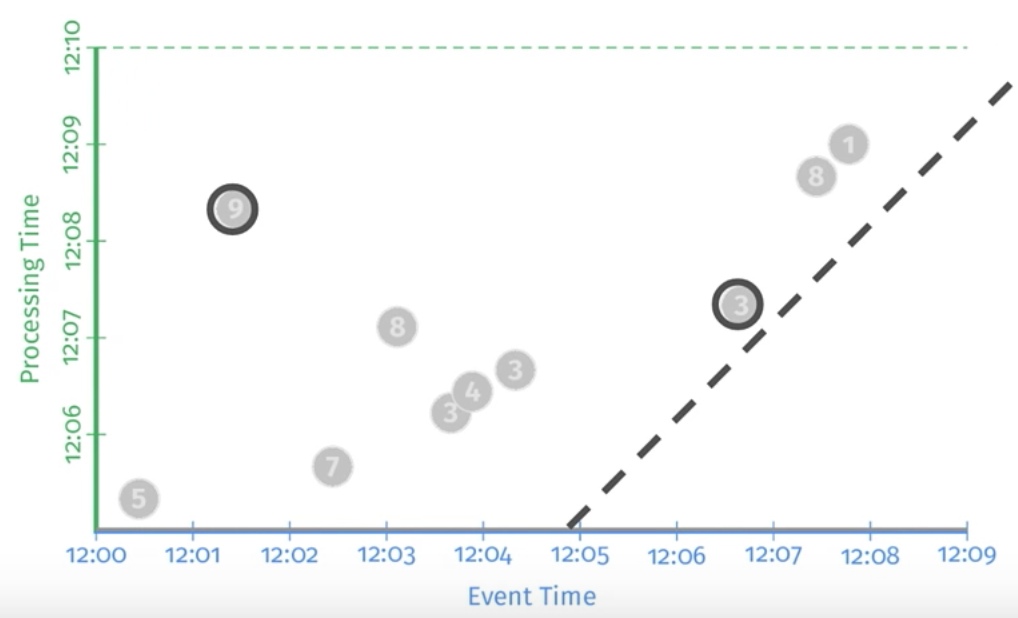
上图中,横轴代表事件发生时间,纵轴代表事件处理事件。在做数据处理的时候,我们往往所理想的情况是数据一出来就被处理完成,图中虚线则代表了这种理想情况。
注:离虚线越近的事件延迟低(图中突出的3事件),反之则延迟高(图中突出的9事件)
Beam模型围绕的四个关键问题
计算的结果是什么?(What results are calculated?)
例如,Sum、Join或是机器学习中训练学习模型等。在Beam SDK中由Pipeline中的操作符指定。
下图展示一个sum示例,累计12:00-12:10分的数字累加。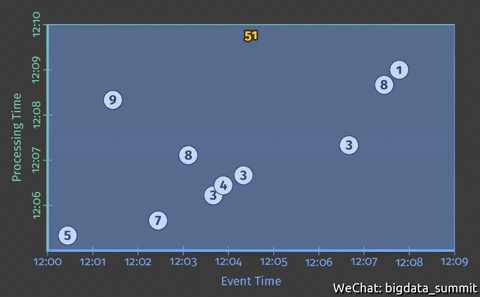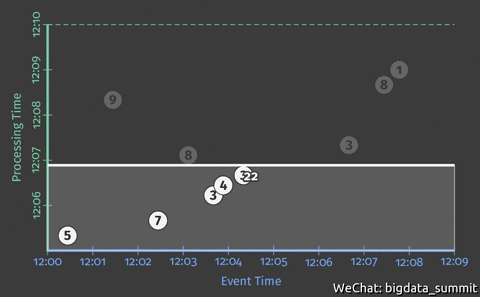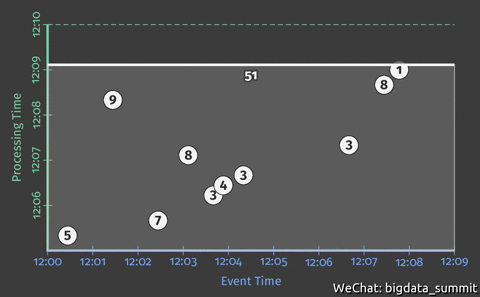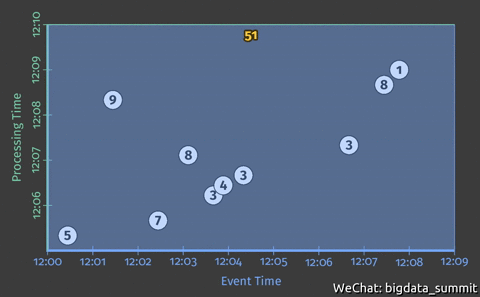
对应Beam代码如下:
通过input.apply()方法,通过beam提供的transforms的Sum进行数据统计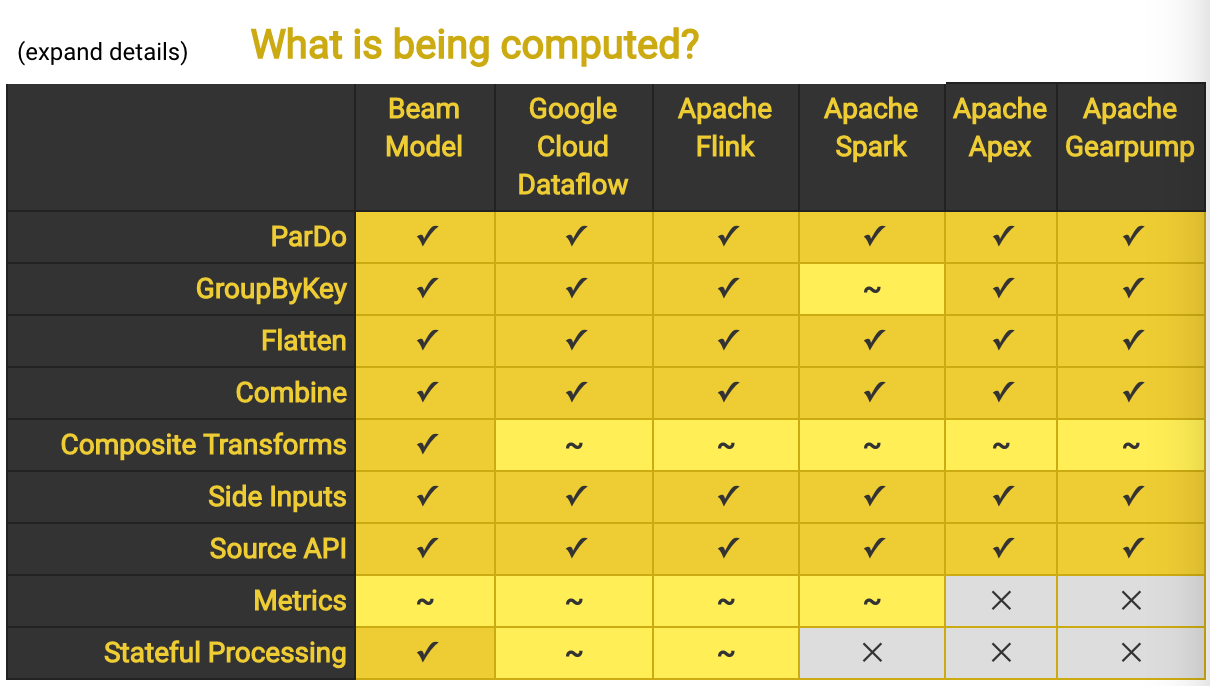
数据在什么范围中计算?(Where in event time are result calculated?)
例如,基于Process-Time的时间窗口,基于Event-Time的时间窗口、滑动窗口等。在BeamSDK中由Pipeline中的窗口指定
假如我们现在想在事件时间横轴上统计每个2分钟时间窗口的整数累加值,即完成如下图动画所示的效果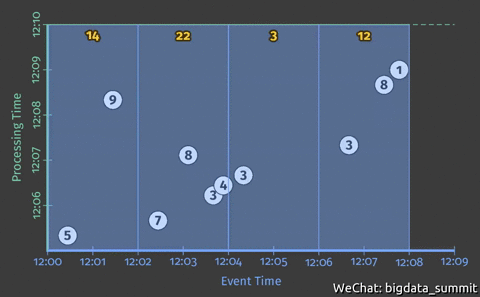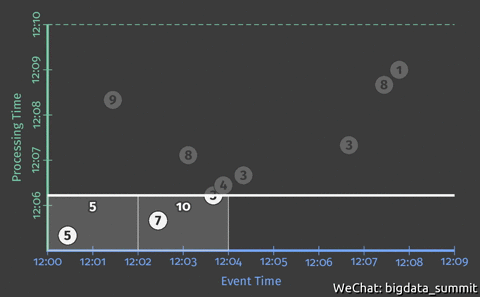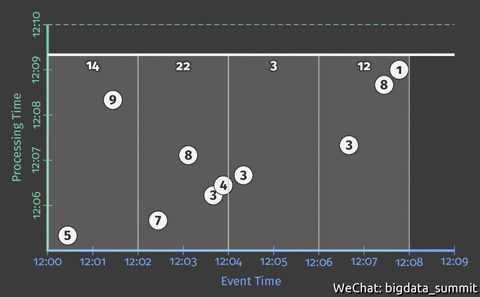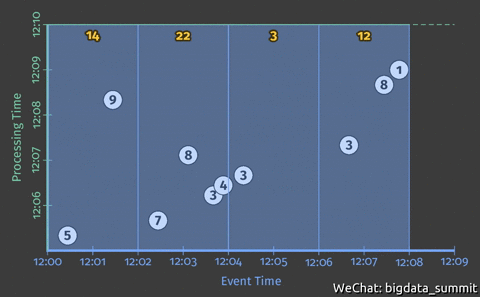
Beam 自动为每个时间窗口创建一个小的批处理作业,在处理时间纵轴 12:10 的时候触发计算。但是这样,我们只能等到最后的一个时间点(12:10)才能得到计算结果。
所支持的窗口列表如下:
何时将结果数据落地?(When in processing time are results materialized?)
例如,在1小时的Event-Time时间窗口中,每隔2分钟,将当前窗口计算结果输出。
在上个问题中,我们以2分钟为间隔,输出每2分钟的统计结果。但是如果用户想提前将结果写入统计结果,那么我们就要对代码做一定的修改。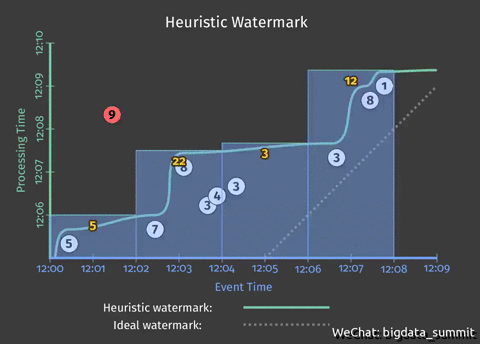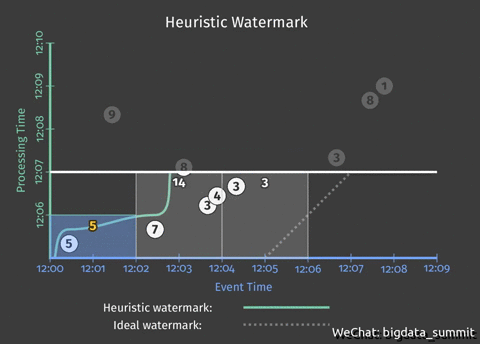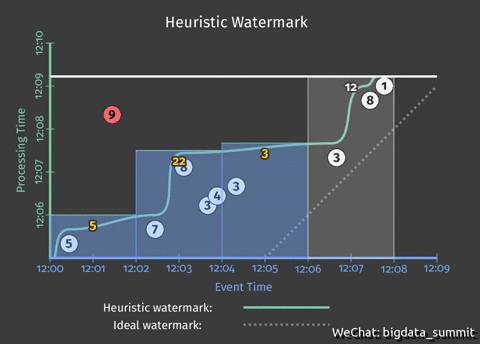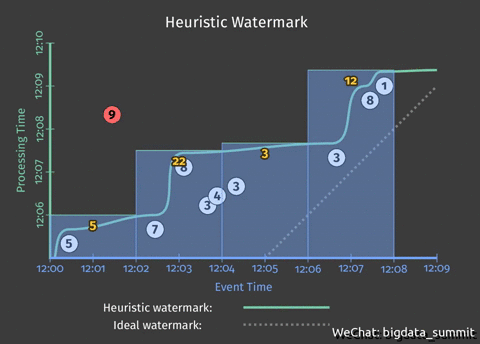
此处引入了触发器(Trigger)以及水平线(Watermark),触发器(Trigger)决定何时将计算结果发射出去,发射太早会丢失一部分数据,丧失精确性,发射太晚会导致延迟变长,而且会囤积大量数据,何时触发器(Trigger)是由水位线(Watermark)来决定的,在Beam SDK中由Pipeline中的水位线和触发器指定
所支持的触发器(Trigger)列表如下: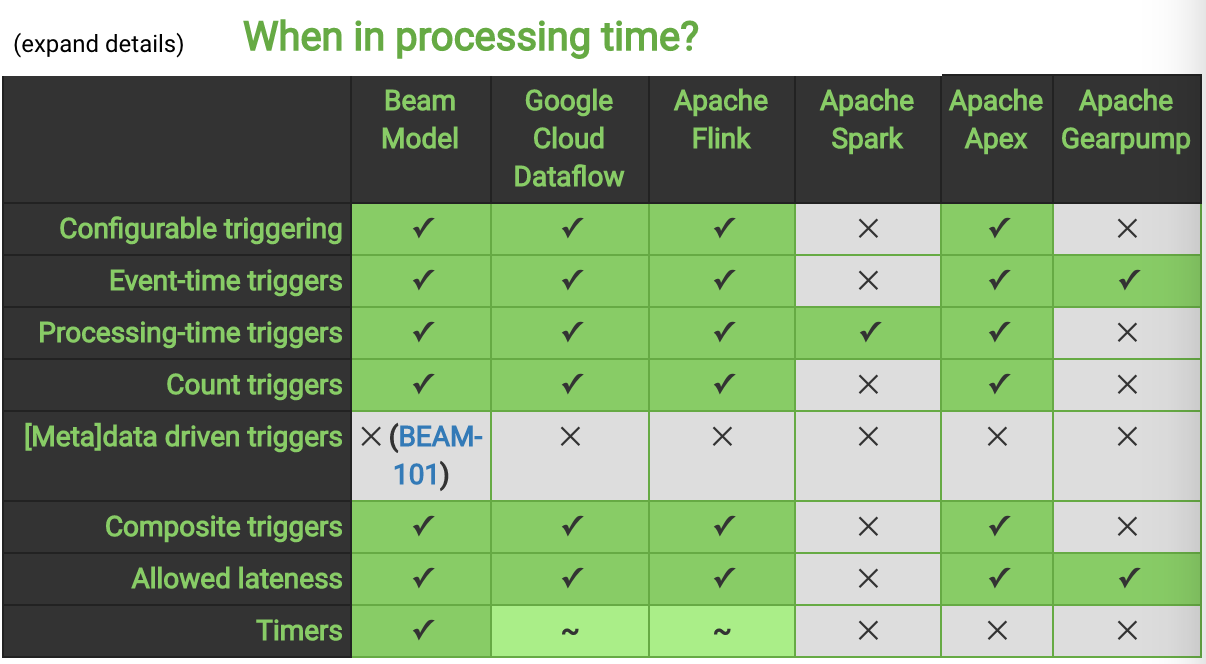
如何对结果进行改进修正?(How do refinements of results relate?)
例如,将迟到数据计算增量结果输出,或是将迟到数据计算结果和窗口内数据计算结果合并成全量结果输出。在Beam SDK中由Accumulation指定
从上个问题的动图中可以看出,虽然我们解决了提前写入事件窗口的统计结果提前写入的问题,但是从动图上可以看出,结果统计遗漏了9这个事件,接下来这步我们就要解决这个问题。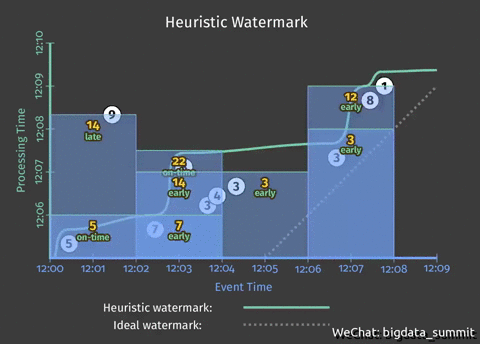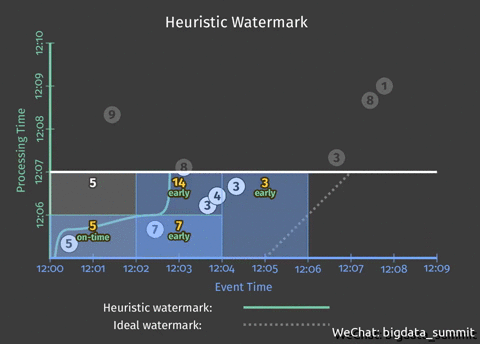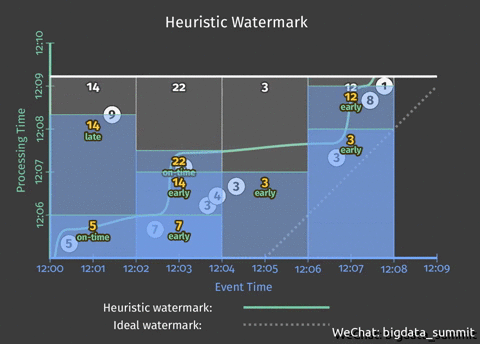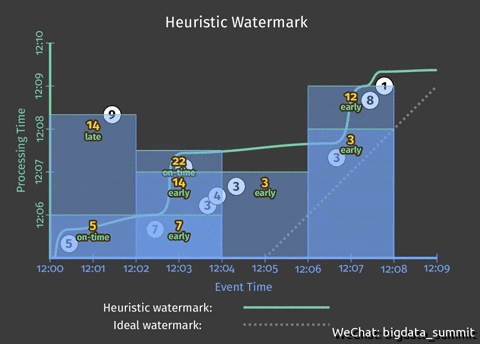
所支持的改进修正功能列表如下:
参考连接:
https://beam.apache.org/documentation/runners/capability-matrix/#cap-summary-what
http://www.jianshu.com/p/357bf071d017
