背景介绍
作为一名大数据开发者,不得不说自从hadoop问世之后,接连而来的各种各样的大数据处理框架层出不穷,而我们则要不断的去学习,运用不同的技术、框架、api,甚至是开发语言以及sdk,去开发项目功能,解决项目问题。
- 平台迁移问题:根据项目的需求,技术的更新迭代,项目性能的要求等等,同样的业务要在不同的框架上运行,可能你就要花费很长一段时间去学习新的框架,新的api。
- 开发工具难抉择:近两年开启的开源大潮,为大数据开发者提供了十分富余的工具。但这同时也增加了开发者选择合适的工具的难度,尤其对于新入行的开发者来说。这很可能拖慢、甚至阻碍开源工具的发展
Apache Beam(原名Google DataFlow)是Google在2016年2月份贡献给Apache基金会的Apache孵化项目,被认为是继MapReduce,GFS和BigQuery等之后,Google在大数据处理领域对开源社区的又一个非常大的贡献。Apache Beam的主要目标是统一批处理和流处理的编程范式,为无限,乱序,web-scale的数据集处理提供简单灵活,功能丰富以及表达能力十分强大的SDK。
Apache Beam项目重点在于数据处理的编程范式和接口定义,并不涉及具体执行引擎的实现。
Apache Beam希望基于Beam开发的数据处理程序可以执行在任意的分布式计算引擎上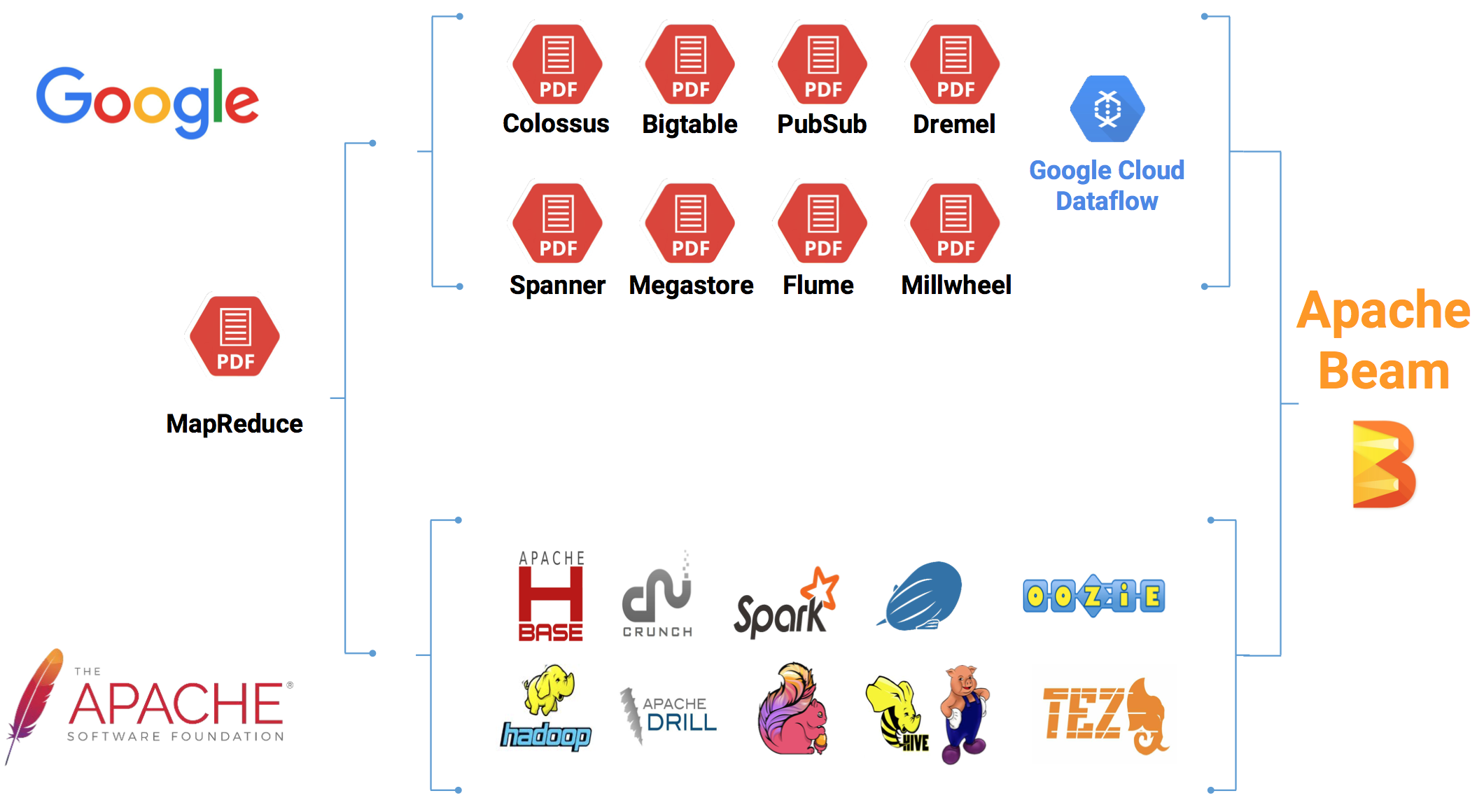
特性
- 统一(Unified):
对于批处理和流式处理,使用单一的编程模型,能够实现批处理(Batch processing)、流处理(Streaming Processing),通常的做法是把待处理的数据集(Dataset)统一,一般会把有界(Bound)数据集作为无界(Unbound)数据集的一种特殊情况来看待,比如Apache Flink便是按照这种方式处理,在差异化的API层之上构建一个统一的API层。 - 可移植(Portable):
在多个不同的计算环境下,都能够执行已经定义好的数据处理Pipeline。也就是说,对数据集处理的定义(即构建的Data Pipeline),与最终所要Deploy的执行环境完全无关。这对实现数据处理的企业是非常友好的,当下数据处理新技术不断涌现,企业数据处理平台也为了能够与时俱进并提高处理效率,当然希望在底层计算平台升级的过程中无需重写上层已定义的Data Pipeline。
目前,Apache Beam项目开发整体来看还处在初期,初步决定底层执行环境支持主流的计算平台:
Apache Apex、Apache Flink、Apache Spark、Google Cloud Dataflow。实际上,Apache Beam的这种统一编程模型,可以支持任意的计算引擎,通过Data Pipeline层与执行引擎层之间开发一个类似Driver的连接器即可实现。 - 可拓展(Extensible):可以实现和分享更多的新SDK、IO连接器、转换操作库等;
核心概念
Pipeline
管道,包装数据处理流程任务
PCollection
分布式数据集,PCollection是管道中每个步骤的输入、输出
Transforms
管道中的每个步骤,它接收一个或者若干个输入PCollection,进行处理后,输出PCollection
I/O sources and sinks
source和sink用于提供数据的输入和输出端点
目前支持如下:
内嵌 I/O 转换
| Language | File-based | Messaging | Database |
|---|---|---|---|
| Java | AvroIO Apache Hadoop File System TextIO XML |
JMS Apache Kafka Amazon Kinesis Google Cloud PubSub |
Apache Hadoop InputFormat Apache HBase MongoDB JDBC Google BigQuery Google Cloud Bigtable Google Cloud Datastore |
| Python | avroio textio |
Google BigQuery Google Cloud Datastore |
拓展 I/O 转换
| Name | Language | JIRA |
|---|---|---|
| AMQP | Java | BEAM-1237 |
| Apache Cassandra | Java | BEAM-245 |
| Apache DistributedLog | Java | BEAM-607 |
| Apache Hive | Java | BEAM-1158 |
| Apache Parquet | Java | BEAM-214 |
| Apache Solr | Java | BEAM-1236 |
| Apache Sqoop | Java | BEAM-67 |
| Couchbase | Java | BEAM-1893 |
| JSON | Java | BEAM-1581 |
| Memcached | Java | BEAM-1678 |
| Neo4j | Java | BEAM-1857 |
| Redis | Java | BEAM-1017 |
| RabbitMQ | Java | BEAM-1240 |
| RestIO | Java | BEAM-1946 |
| TikaIO | Java | BEAM-2328 |
| Cloud Spanner | Java | BEAM-1542 |
基本架构
架构图
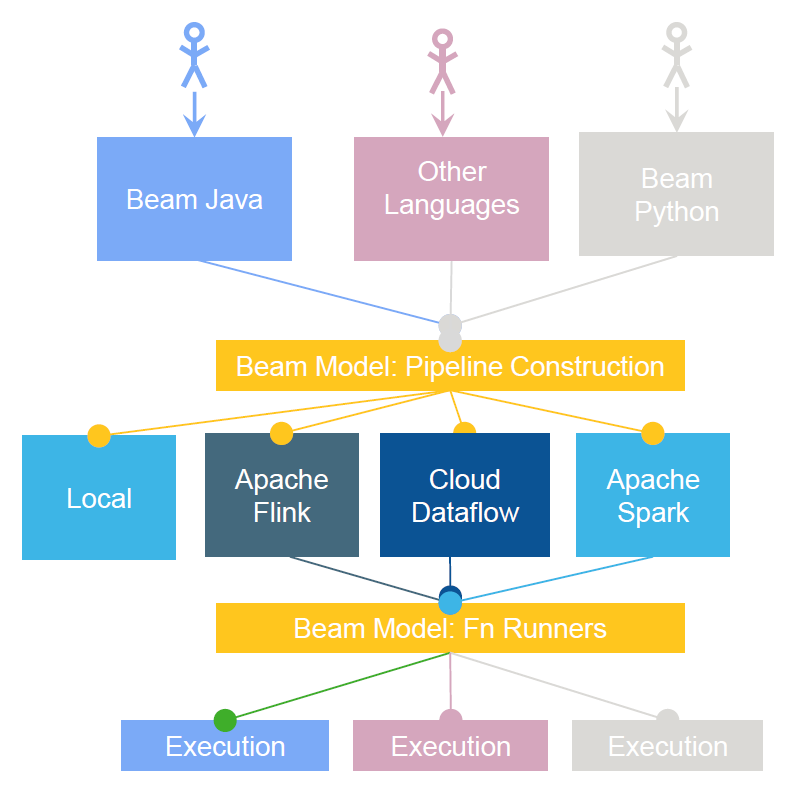
通过上图,我们可以清楚的知道,执行一个流程分以下步骤:
- End Users:选择一种你熟悉的编程语言提交应用
- SDK Writers:该编程语言必须是 Beam 模型支持的
- Library Writers:转换成Beam模型的格式
- Runner Writers:在分布式环境下处理并支持Beam的数据处理管道
- IO Providers:在Beam的数据处理管道上运行所有的应用
- DSL Writers:创建一个高阶的数据处理管道
Beam核心组成部分
- Beam SDK
Beam SDK提供一个统一的编程接口给到上层应用的开发者,开发者不需要了解底层的具体的大数据平台的开发接口是什么,直接通过Beam SDK的接口,就可以开发数据处理的加工流程,不管输入是用于批处理的有限数据集,还是流式的无限数据集。对于有限或无限的输入数据,Beam SDK都使用相同的类来表现,并且使用相同的转换操作进行处理。Beam SDK可以有不同编程语言的实现,目前已经完整地提供了Java,python的SDK还在开发过程中,相信未来会有更多不同的语言的SDK会发布出来。 - Beam Pipeline Runner
Beam Pipeline Runner将用户用Beam模型定义开发的处理流程翻译成底层的分布式数据处理平台支持的运行时环境。在运行Beam程序时,需要指明底层的正确Runner类型。针对不同的大数据平台,会有不同的Runner。目前Flink、Spark、Apex以及谷歌的Cloud DataFlow都有支持Beam的Runner。
语言(Language)
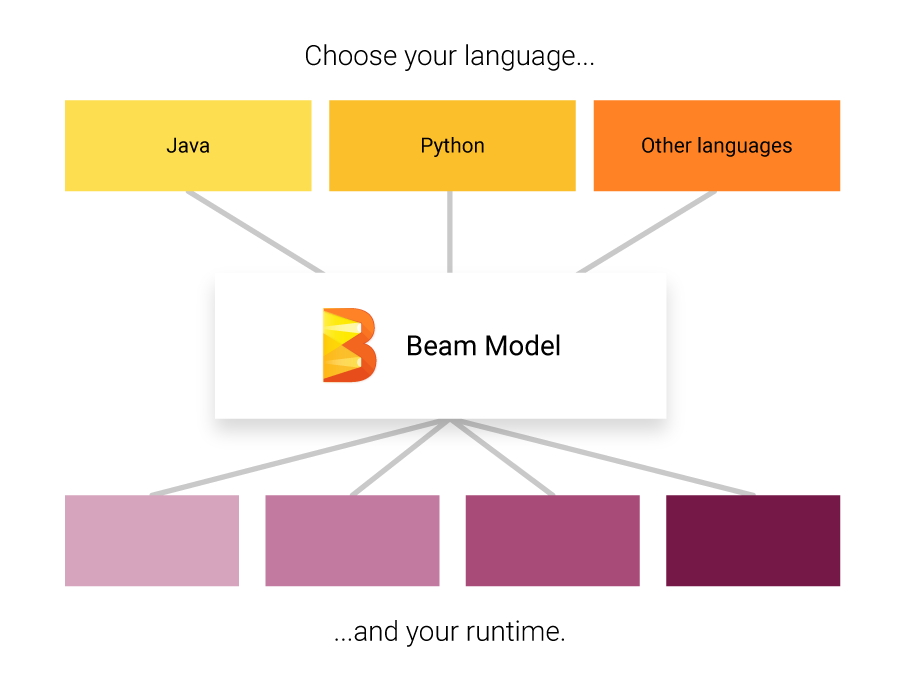
运行器(Runner)

总结
Apache Beam的Beam Model对无限乱序数据流的数据处理进行了非常优雅的抽象,“WWWH”四个维度对数据处理的描述,非常清晰与合理,Beam Model在统一了对无限数据流和有限数据集的处理模式的同时,也明确了对无限数据流的数据处理方式的编程范式,扩大了流处理系统可应用的业务范围,例如,Event-Time/Session窗口的支持,乱序数据的处理支持等。Apache Flink,Apache Spark Streaming等项目的API设计均越来越多的借鉴或参考了Apache Beam Model,且作为Beam Runner的实现,与Beam SDK的兼容度也越来越高。
目前apache beam的开发处于初步阶段,对python的支持还在开发中,对java的支持的内容相对比较丰富,支持的runner也会逐步增加,实现平台迁移的可移植,降低/解决大数据开发者框架选择的问题。
参考链接:
https://www.infoq.com/presentations/apache-beam
https://beam.apache.org/documentation/io/built-in/
http://www.cnblogs.com/smartloli/p/6685106.html
